The Multistream Formalism
"Tandem" Multistream Recognition
This year we have continued to investigate the Tandem Acoustic
Modelling approach developed earlier in the project, in which a neural
network is used as a first stage of processing before a conventional
Gaussian mixture model speech recogniser. Our investigations focused
on trying to understand the large improvements shown by this system by
examining a range of variants to test specific hypotheses. For
instance, we tried replacing the neural network in the first stage
with a second Gaussian mixture model (GMM) to estimate the initial
posterior probabilities. The results give us some insight into why
the neural net performs better, as the figure below illustrates:
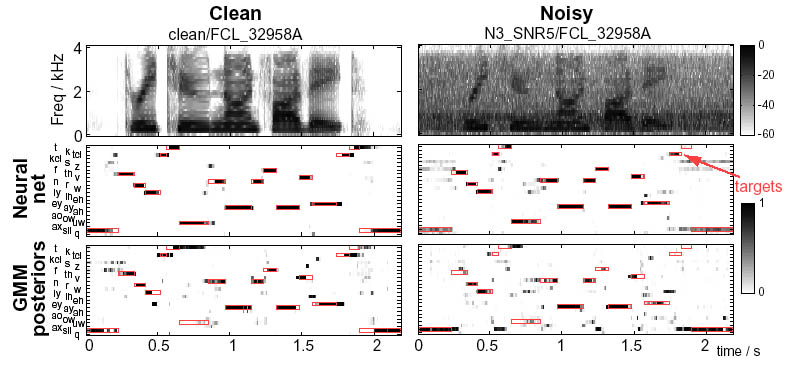
We see that even for a clean speech sample (left column), a GMM
trained on the same data as the neural net has a lot of trouble, for
instance completely missing the vowel of "two". At 5dB
signal-to-noise ratio (the right side), the difference between neural
net and GMM is very pronounced, with the GMM tending to mark noisy
segments as background ("sil") while the neural net is much more
precise.
RESPITE is a Winner!
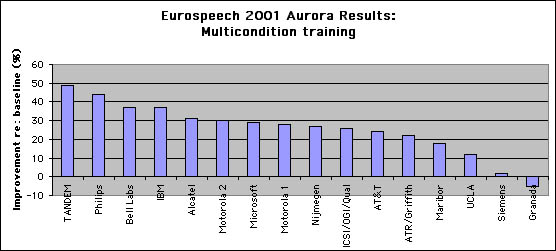
Our Tandem system was one of the participants in a large comparison
session at the recent Eurospeech conference in Denmark in which over
20 papers were presented describing systems for the same noisy digits
task. All the foremost speech research labs in the world
participated, including IBM, Lucent, Microsoft etc. Our Tandem system
achieved the best overall word error rate, and the largest margin of
improvement (50% better than the standard baseline) among systems
trained on noisy examples, as shown in the chart below:
Multiband With Contaminated Training Data
Last year we introduced a new noise robust approach based on the use of
a particular training procedure (based on data contamination) in a particular
architecture (the multi-band paradigm). In this framework, we expected
to remove the drawbacks of both the corpus contamination approach which
is the dependency to noise spectral characteristics, and the multi-band
architecture which is its inefficiency in case of wideband noise.
Recently, this method has been tested on the AURORA 2 task and compared
to other robust methods:
-
spectral subtraction
-
J-RASTA filtering
-
missing data compensation
-
matching noise conditions
The matching noise conditions corresponds to a reference system in which training has been performed in the same noise conditions as the tests (cf. multi-condition training of the AURORA2 task)
Two different configurations of our multiband approach have been compared:
-
Conf. 1: a large system with over 1.5 million parameters
-
Conf. 2: a small system with about 300,000 parameters (that is the same order as other methods)
The following figures show that, even for the smaller configuration, our approach leads to very good performance
on different kinds of additive noise, without any a priori knowledge of the noise characteristics.
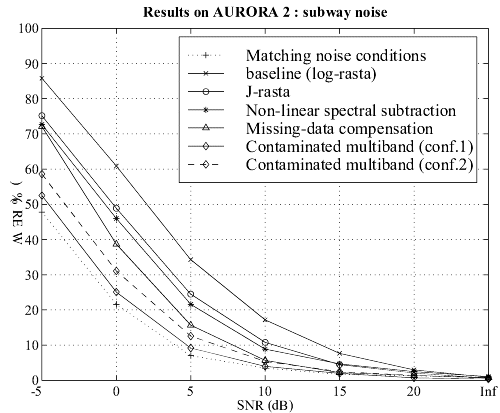
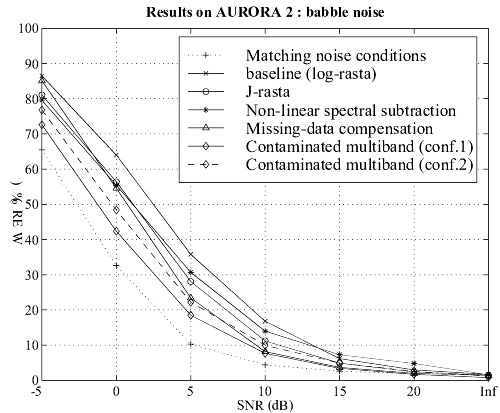
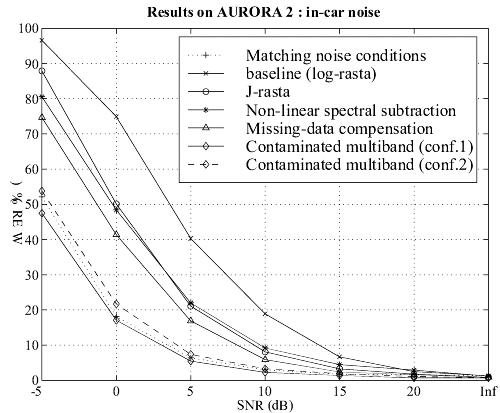
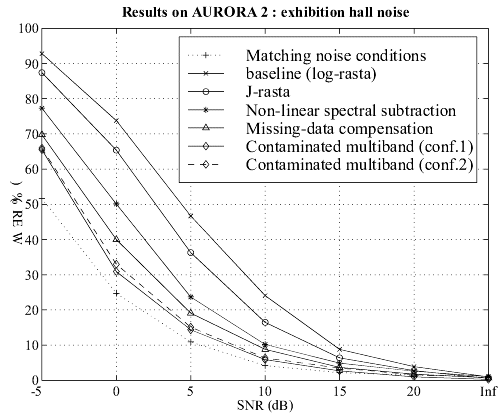
Figure 1-4: Comparative results on four kinds of noise
(subway, babble, in-car and exhibition hall). Click on the image to see
it full size.
Multistream Combination Based On A Model For The Use Of Context In Human Perception
A study was made to see whether a two stage model for the human perception of speech and text categories (first stage using only local sensory data, second using higher level data from a wider context) could usefully be adapted as a new variant of HMM/ANN based ASR. Test performance of the ECPC (Error Correction Posteriors Combination) model was not, however, significantly different to that for the usual FC model.
Multistream ASR Techniques Tested On EEG Recognition
Like speech recognition in noise, thought recognition from EEG data (electric field measurements from the scalp surface) also has to contend with a high degree of unaccountable signal variation. Initial multiband classifier-decoder experiments, though providing an interesting new field of potential application, showed that direct application of multiband ASR to EEG recognition does not give significant improvement over a fullband classifier baseline, and that HMMs are not able to model the time structure in raw EEG data. We believe that the limited data streams available were not sufficiently complementary.