It is natural to think of Auditory Scene Analysis as a pre-processing stage for robust automatic speech recognition: first separate out the speech evidence from that for other sound sources, then present this evidence to the recogniser. In contrast to other methods for achieving robustness, ASA requires no model of the noise, relying only on low-level grouping principles which reach down to the properties of the speech preduction and perception systems, and to the physics of sound.
However, ASA will never recover all the speech evidence. There will be some spectro-temporal regions which are dominated by other sources [fig - the usual siren - on p10 of /home/splashbase/pdg/docs/us-trip/us-foils.frame]. There is an analogy with visual occlusion: just as it is posssible to recognise objects which are partly hidden by other objects, it is possible to recognise speech without having the complete spectrum available. This is the essence of the 'missing data' approach:
You can think of the effect of (1) as defining a mask which is laid over the speech spectrum. Only pixels under the holes in the mask can be used for recognition. This is illustrated below: the top figure is an auditory spectrogram for a spoken digit sequence '439' contaminated by factory noise at 10dB SNR. The figures below are examples of masks for this utterance. The mask is black where speech dominates.
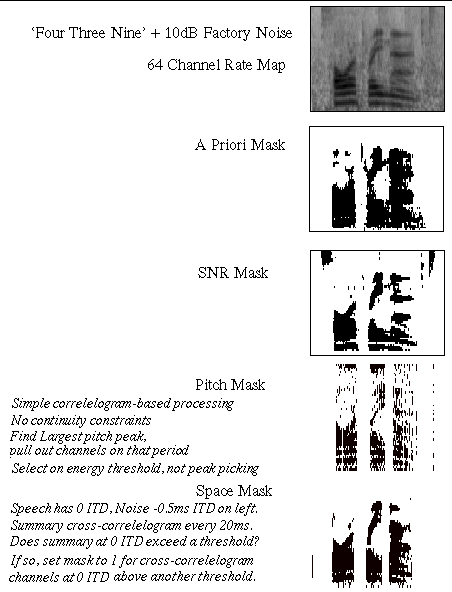
There are two approaches to problem 2. One can either estimate the missing values and then proceeed as normal (missing data imputation) or use the distribution of the remaining values alone (marginalisation). In SpandH, both these techniques have been formulated for statistical recognisers based on Hidden Markov Models. Data imputation is best-performed on the basis of the conditional distribution for the missing data given the present data and the recognition hypothesis. Marginalisation can be improved by the additional use of counter-evidence: even if we don't know the true speech value for some time-frequency pixel we can put a bound on it: the speech energy cannot be greater than the energy in the mixture. Thus speech sounds wich require more energy than the total available can be rejected. Both techniques can also benefit from recognising on the basis of spectral peaks only.
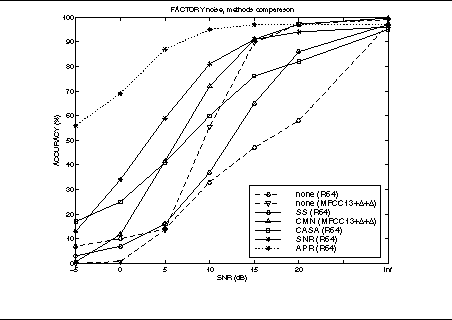
Some results are given below. The task here is connected digit recognition and speech is mixed with factory noise in varying proportions. Word recognition accuracy is plotted against Sginal to Noise ratio.