In the process of domain knowledge acquisition, the main problem that needs to be addressed is how to distinguish text semantics and domain knowledge. Often different acquisition sources are written for different audience and similar facts might be presented differently. Therefore, in DB-MAT domain knowledge concerns facts which are true in the given domain (namely oil-processing) and which were extracted manually from various multilingual resources [Angelova & Bontcheva 97].
In order to detect whether a text unit expresses a domain fact we rely on a previously acquired taxonomy of the domain. This taxonomy can be built in several ways: ( i) from termonological dictionaries; ( ii) hand-crafted from the acquisition sources; ( iii) using statistical methods on a corpus with domain texts. Since we did not have a sufficiently large corpus, we only applied the first two methods.
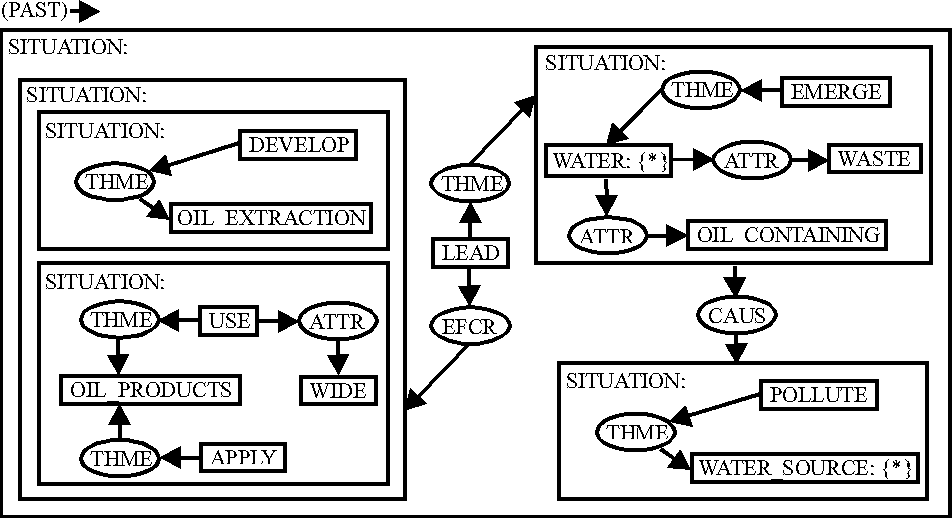
Now let us consider the following example sentence: The development
of oil extraction and the wide use and application of oil products led to
the emergence of oil-containing waters and the subsequent pollution of water
sources.
Figure 1![]() shows the semantics of this text encoded in
conceptual graphs. However, as evident in
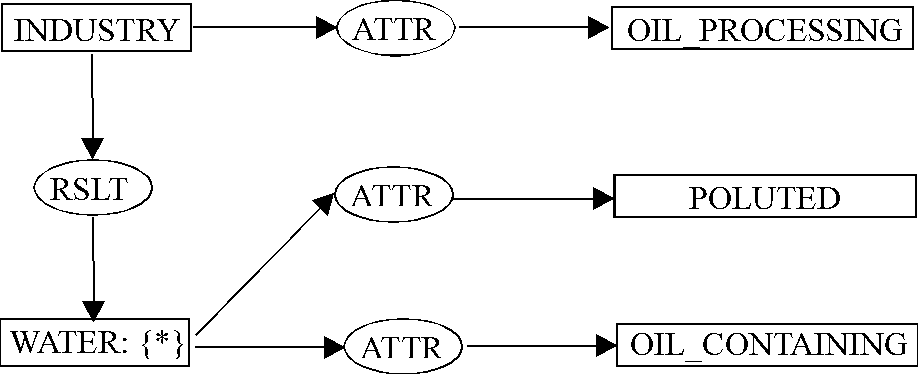
Figure 2, the acquired domain fact is quite
different. The fact was acquired because there are more than 2 domain
concepts which occur in the sentence and similar relationship between them
has not been already established. The main difference between the semantics
of this sentence and the acquired fact comes from the paraphrase of the
subject as the more general oil-processing industry.
shows the semantics of this text encoded in
conceptual graphs. However, as evident in
Figure 2, the acquired domain fact is quite
different. The fact was acquired because there are more than 2 domain
concepts which occur in the sentence and similar relationship between them
has not been already established. The main difference between the semantics
of this sentence and the acquired fact comes from the paraphrase of the
subject as the more general oil-processing industry.