


Copyright © Roger K. Moore | contact Site designed using Serif WebPlus X6
RESEARCH
I have over forty years experience in speech technology R&D, and much of my research has been based on insights derived from human speech perception and production. I built my first automatic speech recogniser - EARS (Electronic Apparatus for Recognising Speech) in 1972, and in the mid-1970s I introduced the Human Equivalent Noise Ratio (HENR) - a vocabulary-independent measure of the goodness of an automatic speech recogniser based on a computational model of human word recognition. In the 1980s, I published HMM Decomposition - a powerful method for recognising multiple simultaneous signals (such as speech in noise) based on observed properties of the human auditory system. During the 1990s and more recently, I've continued to champion the need to understand the similarities and differences between human and machine spoken language behaviour.
Since joining Sheffield I've embarked on research that is aimed at developing computational models of Spoken Language Processing by Mind and Machine, and I'm currently working on a unified theory of spoken language processing called PRESENCE (PREdictive SENsorimotor Control and Emulation). PRESENCE weaves together accounts from a wide variety of different disciplines concerned with the behaviour of living systems - many of them outside the normal realms of spoken language - and compiles them into a new framework that is intended to breath life into a new generation of research into spoken language processing, especially for Autonomous Social Agents and Human-Robot Interaction. I am also interested in the relationship between human and animal communication, and have instigated several research activities under the banner of Vocal Interactivity in-and-between Human, Animals and Robots (VIHAR).
At the more practical end of the scale, I’m involved in collaborations aimed at Clinical Applications of Speech Technology (particularly for individuals with speaking difficulties) and Creative Applications of Speech Technology through interactions with colleagues from the performing arts.

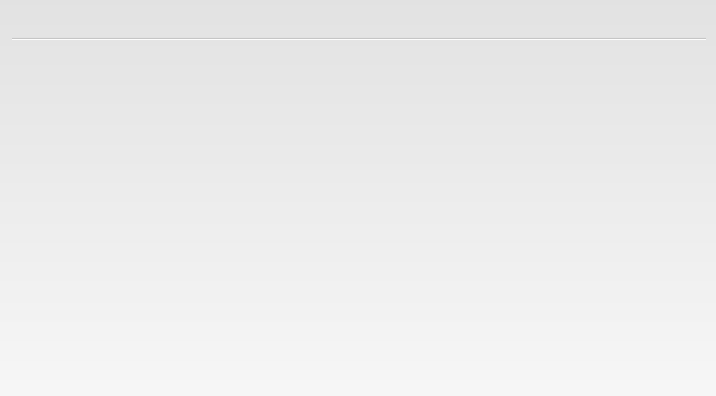
PRESENCE is a new architecture for speech-based interaction that is founded on the premise that future progress depends, not on how to "bridge the gap" between speech science and speech technology, but on both communities seeking to assimilate wider research findings on the behaviour of living systems in general and the cognitive abilities of human beings in particular. PRESENCE intentionally blurs the distinction between the core components of a traditional spoken language dialogue system and, as a result, cooperative and communicative behaviour emerges as a by-product of an architecture that is founded on a model of co-action in which the system has in mind the needs and intentions of a user, and a user has in mind the needs and intentions of the system.
More >>
In pursuing PRESENCE-based approaches to modelling spoken language, I've become increasingly drawn into studying vocalisation in general, whether it is performed by human beings, animals or robots. I'm currently developing synthesisers for mammalian, insect and dolphin vocalisations, and embedding them in behavioural simulations implemented in Pure Data and in real-time embodiments using e-puck, Create and RoboKind robots. My aim is to demonstrate that many of the little-understood paralinguistic features exhibited in human speech (including emotion) are derived from characteristics that are shared by living systems in general. Modelling such behaviours in this wider context should eventually enable us to implement usable and effective interaction with artificial intentional agents such as robots.
More >>

The use of technology to manipulate and alter human or machine voices interest me greatly, and I’m particularly keen to use such techniques to create voices for animated agents and robots that are ‘appropriate’ to their visual and behavioural affordances. I'm also becoming increasingly involved in using such manipulations to explore more creative possibilities, and I’ve recently enjoyed very productive interactions with colleagues from the performing arts. In particular I work closely with Dr. Chris Newell based at the University of Hull. As well as pursuing various collaborative projects, Chris and I are slowly compiling a book entitled The Art of Artificial Voices in which we explore the creative uses of spoken language from both the technological and the performance perspectives.
More >>

One of the areas in which advanced speech technology algorithms can really make a difference to people is in situations where individuals have serious difficulties in hearing or speaking. The Sheffield Speech and Hearing group has a long history of research in this area, and has devoted significant effort to developing assistive technology that is tailored to the needs of specific individuals, such as dysarthric speakers with cerebral palsy or laryngectomy patients. My research is focused on the development of low-dimensionality speech synthesis and how to optimise real-time control for users with severe motor impairment. I’m currently working on an articulatory synthesiser (based on an acoustic waveguide model of the human vocal tract) which incorporates a novel, yet anatomically parsimonious, tongue.
More >>
More >>

RESEARCH PROJECTS
Ongoing
- SRAM: Speech Rehabilitation from Articulator Movement (NIHR Invention for Innovation - i4i)
- IGLU: Interactive Grounded Language Understanding (CHIST-ERA)
Completed
- ACORNS: Acquisition of COmmunication and Recognition Skills (EU FP6 FET STREP)
- AMI: Augmented Multi-Party Interaction (EU FP6 IST IP)
- AMIDA: Augmented Multiparty Interaction with Distance Access (EU FP6 IST IP)
- CA-RoboCom: Robot Companions for Citizens (FET Flagship Coordination Action)
- COMPANIONS: Intelligent, Persistent, Personalised Multimodal Interfaces to the Internet (EU FP6 IST IP)
- CREST: Creative Speech Technology (EPSRC Network)
- DiSArM: Digital Speech Recovery from Articulator Movement (NIHR Invention for Innovation - i4i)
- EASEL: Expressive Agents for Symbiotic Education and Learning (EU FP7)
- HUMAINE: Human-Machine Interaction Network on Emotion (EU FP6 Network/Association)
- Redress: Recognition and Reconstruction of Speech following Laryngectomy (UK Action Medical Research)
- SCALE: Speech Communication with Adaptive LEarning (EU Marie Curie)
- SERA: Social Engagement with Robots and Agents (EU FP7 IST STREP)
- S2S: Sound to Sense (EU Marie Curie)

RESEARCH COLLABORATIONS
Internal
- SPandH: Speech and Hearing Research Group
- CAST: Clinical Applications of Speech Technology
- CATCH: Centre for Assistive Technology and Connected Healthcare
- SCentRo: Sheffield Robotics
External
PURE DATA
Much of my personal research (and teaching) is performed using the Pure Data (Pd) dataflow programming language. Pd provides a real-time graphical programming environment (authored by Miller Puckette – “The diagram is the program”) that is designed to operate on audio, graphical and video signals. Pd is a free alternative to Max/MSP, and not only does it make it easy to implement real-time audio input/output, but it is especially efficient for rapid prototyping and creative research. Go to my Pd downloads page >>


Having been actively involved in speech technology R&D for over four decades, I’m often called upon to deliver my personal perspective on the progress that’s been made in the past and the prospects we’re likely to witness in the years to come. In order to inform these views, I’ve not only conducted a number of surveys of the speech technology R&D community, but I’ve also exploited the ability of my Human Equivalent Noise Ratio (HENR) model to extrapolate automatic speech recogniser performance into the future. In addition, I maintain a timeline of significant historical events in our field (including some infamous quotations and notable predictions) which it is hoped will provide a useful resource for students and researchers interested in learning how the speech technology field has developed over the years.
More >>
More >>

Whilst there is considerable interest in the possibility of people interacting with ‘intelligent’ agents for a wide range of applications, as yet there is no underpinning science as to how create such artefacts to ensure that they are capable of providing an effective and sustainable interaction. This is especially true in the case of human-robot interaction where the look, sound and behaviour of a robot may not be consistent - a situation that can trigger feelings of eeriness and repulsion in the users. I have developed the first mathematical model of this so-called ‘uncanny valley’ affect (published in Nature), and I am currently investigating the implications for designing autonomous social agents (such as robots) whose visual, vocal, cognitive and behavioural ‘affordances’ are appropriate to the role for which they are designed.
More >>